What is DynamoDB?
The hosted NoSQL database DynamoDB is made available by Amazon Web Services (AWS). It provides:
- scalable performance that is reliable;
- a managed experience, preventing the need for SSH access to servers to update the cryptographic libraries;
- a compact, straightforward API that supports both basic key-value access and sophisticated query patterns.
The following use cases suit DynamoDB extremely well:
Applications with severe latency constraints and high data volumes. JOINs and sophisticated SQL techniques can make queries slower as your data volume grows. Your queries will execute with predictable latency using DynamoDB, even if they are above 100 TBs in size!
Utilizing AWS Lambda, serverless applications. In reaction to event triggers, AWS Lambda offers auto-scaling, stateless, ephemeral compute. Building Serverless applications is a fantastic fit for DynamoDB because it supports authentication & authorisation using IAM roles and is accessible via an HTTP API.
Sets of data with well-known, basic access patterns. DynamoDB is a quick, dependable option if you’re creating suggestions and serving them to users because of its straightforward key-value access patterns.
DynamoDB query process
The hosted NoSQL database DynamoDB is made available by Amazon Web Services (AWS). It provides:
- scalable performance that is reliable;
- a managed experience, preventing the need for SSH access to servers to update the cryptographic libraries;
- a compact, straightforward API that supports both basic key-value access and sophisticated query patterns.
The following use cases suit DynamoDB extremely well:
Applications with severe latency constraints and high data volumes. JOINs and sophisticated SQL techniques can make queries slower as your data volume grows. Your queries will execute with predictable latency using DynamoDB, even if they are above 100 TBs in size!
Utilizing AWS Lambda, serverless applications. In reaction to event triggers, AWS Lambda offers auto-scaling, stateless, ephemeral compute. Building Serverless applications is a fantastic fit for DynamoDB because it supports authentication & authorisation using IAM roles and is accessible via an HTTP API.
Sets of data with well-known, basic access patterns. DynamoDB is a quick, dependable option if you’re creating suggestions and serving them to users because of its straightforward key-value access patterns.
Examples of sort key criteria include the following:
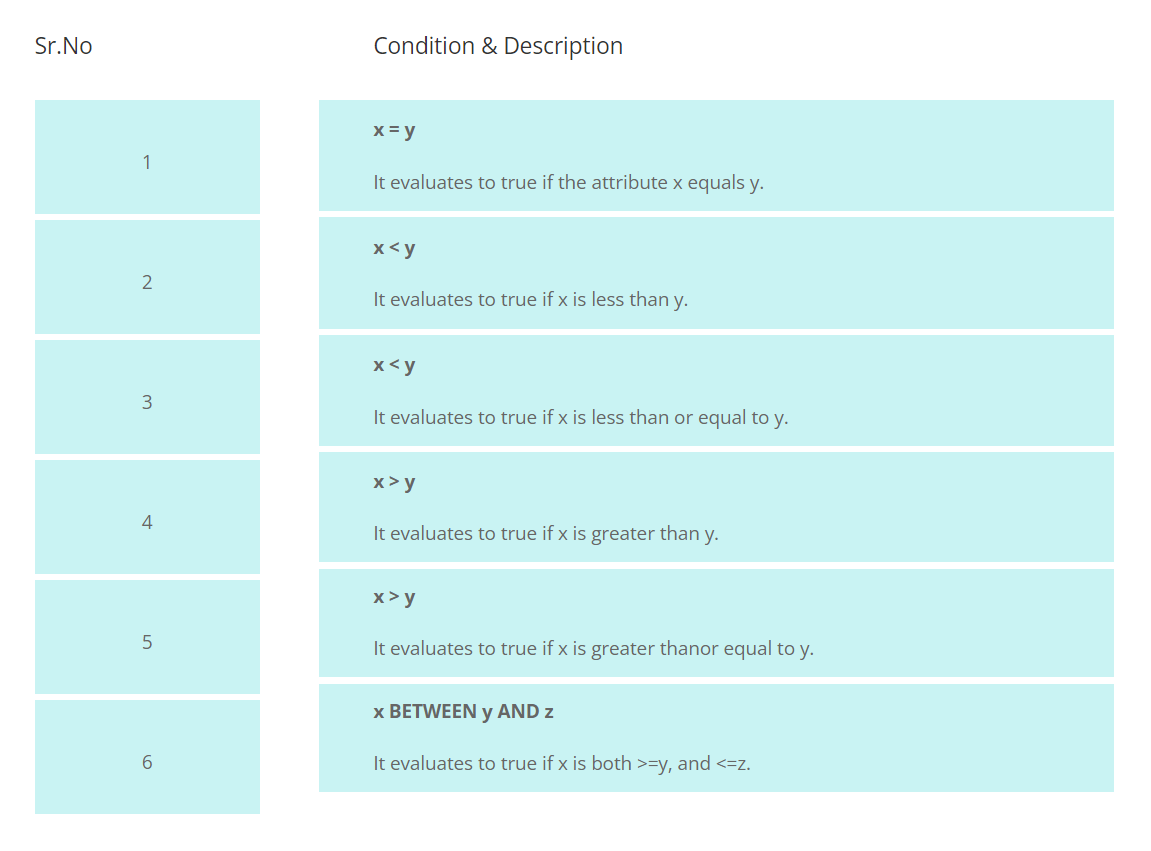
Additionally, DynamoDB supports the following operations: begins with (x, substr) (x, substr)
If attribute x begins with the supplied string, it evaluates to true.
The following circumstances must meet specific criteria:
- Names for attributes must begin with a character from the a-z or A-Z set.
- An attribute name’s second character must belong to the a-z, A-Z, or 0-9 set.
- Reserved terms cannot be used in attribute names.
Names for attributes that do not adhere to the aforementioned restrictions can define a placeholder.
The query executes retrievals in sort key order while applying any available condition and filter expressions. An empty result set is always returned by queries when there are no matches.
Results are always returned in ascending order by customizable default, sort key order, and data type order.
Querying with Java
You can query tables and secondary indices using Java queries. They have the opportunity to define sort keys and conditions, but they only require the declaration of partition keys and equality conditions.
Creating an instance of the DynamoDB class, a Table class instance for the target table, and invoking the query method of the Table instance to receive the query object are the usual prerequisites for a query in Java.
An ItemCollection object containing every returned item is included in the answer to the query.
Detail-oriented querying is seen in the example below.
DynamoDB dynamoDB = new DynamoDB (
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1"));
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
Item item = null;
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.toJSONPretty());
}There are several other optional arguments supported by the query technique. How to use these parameters is shown in the example below:
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn and ResponseTM > :nn_responseTM")
.withFilterExpression("Author = :nn_author")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1")
.withString(":nn_responseTM", twoWeeksAgoStr)
.withString(":nn_author", "Member 123"))
.withConsistentRead(true);
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}You can also look over the next more extensive example.
Note: The program that follows might use a data source that has already been established. Obtain supporting libraries and build appropriate data sources before attempting to run (tables with required characteristics, or other referenced sources).
The AWS Toolkit, an AWS credential file, and an Eclipse AWS Java Project are also used in this example.
package com .amazonaws .codesamples .document;
import java .text .Simple Date Format;
import java.util .Date;
import java.util. Iterator;
import com. amazonaws. auth. profile. ProfileCredentialsProvider;
import com .amazonaws. services.dynamodbv2.AmazonDynamoDBClient;
import com. amazonaws.services.dynamodbv2.document.DynamoDB;
import com. amazonaws.services.dynamodbv2.document.Item;
import com. amazonaws.services.dynamodbv2.document.ItemCollection;
import com. amazonaws.services.dynamodbv2.document.Page;
import com. amazonaws.services.dynamodbv2.document.QueryOutcome;
import com. amazonaws.services.dynamodbv2.document.Table;
import com. amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com. amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class QueryOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "Reply";
public static void main(String[] args) throws Exception {
String forumName = "PolyBlaster";
String threadSubject = "PolyBlaster Thread 1";
getThreadReplies(forumName, threadSubject);
}
private static void getThreadReplies(String forumName, String threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", replyId));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\ngetThreadReplies results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}Finding Every Item with a Specific Partition Key
We discussed working with individual Items at once in our previous chapter. That may be helpful in certain circumstances, such as when working with Users. Whether fetching a User’s profile or updating a User’s name, we typically manipulate one User at a time.
In other circumstances, such as when working with Orders, it is less beneficial. Sometimes we want to grab a certain Order, while other times we might want to show all the Orders for a specific User. For each User’s Orders, it would be inefficient to keep the various partition keys and then query those Items separately.
Let’s look at how the Query API call can be used to fulfill the latter request. We will first gather all of our daffyduck User’s Orders.
$ aws dynamodb query \
--table-name UserOrdersTable \
--key-condition-expression "Username = :username" \
--expression-attribute-values '{
":username": { "S": "daffyduck" }
}' \
$LOCALThe entire set of Daffy’s Orders is back:
{
"Count": 4,
"Items": [
{
"OrderId": {
"S": "20160630-28176"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "88.3"
}
},
{
"OrderId": {
"S": "20170608-10171"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "18.95"
}
},
{
"OrderId": {
"S": "20170609-25875"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "116.86"
}
},
{
"OrderId": {
"S": "20171129-29970"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "6.98"
}
}
],
"ScannedCount": 4,
"ConsumedCapacity": null
}
This is quite helpful. We could display all of a User’s Orders on an Orders overview page, with the option for the User to dig down to a specific Order if they so wished.
Using Key Expressions
Instead of returning all Items with a specific HASH key when requesting the return of Items, you might want to further restrict the Items that are returned.
For instance, when creating our table, we determined that we wanted to respond to the question:
Give me every OrderId for a specific Username.
Although this is helpful generally, we might want to add something at the end, similar to the WHERE clause in SQL:
Give me every OrderId for a specific Username that was placed in the last six months.
OR
Please provide me with all OrderIds for a certain Username where the Amount exceeded $50.
There are two ways we might approach this further segmentation. Building the element we wish to query into the RANGE key is the best course of action. This enables us to query our data using Key Expressions, which enables DynamoDB to identify the Items that satisfy our Query rapidly.
Filtering based on non-key properties is a different approach to handling this. Although less effective than Key Expressions, this can still be beneficial under the right circumstances.
We’ll see how to use Key Expressions to filter our findings in this section. We’ve already specified the HASH key we wish to use with our Query using the —key-condition-expression option. A RANGE key value or an expression that operates on that RANGE key can also be included.
Recall that we formatted OrderId as OrderDate-RandomInteger in our RANGE key. We may use the expression syntax to query by order date by starting with the OrderDate in our RANGE key.
For instance, we would ensure that our OrderId was between “20170101” and “20180101” if we needed all Orders from 2017:
aws dynamodb query \
--table-name UserOrdersTable \
--key-condition-expression "Username = :username AND OrderId BETWEEN :startdate AND :enddate" \
--expression-attribute-values '{
":username": { "S": "daffyduck" },
":startdate": { "S": "20170101" },
":enddate": { "S": "20180101" }
}' \
$LOCALOur results return three Items rather than all four of Daffy’s Orders:
{
"Count": 3,
"Items": [
{
"OrderId": {
"S": "20170608-10171"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "18.95"
}
},
{
"OrderId": {
"S": "20170609-25875"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "116.86"
}
},
{
"OrderId": {
"S": "20171129-29970"
},
"Username": {
"S": "daffyduck"
},
"Amount": {
"N": "6.98"
}
}
],
"ScannedCount": 3,
"ConsumedCapacity": null
}Daffy’s fourth order was in 2016 so it did not satisfy our Key Expression.
Although there are some restrictions, these Key Expressions are quite helpful in providing more precise query patterns. The necessary information must be directly incorporated into the keys because the Key Expression can only be used with the HASH and RANGE keys. Additionally, it restricts the variety of query patterns you might use. You cannot perform a Key Expression based on the Order Amount if you decide to start your RANGE key with the OrderDate.
Choosing a more specific Query
The query result is delivering a full Item in the above answers, satisfying our query requirement. In our previous example with tiny Items, it’s not too bad. It can raise your response size in unfavorable ways with larger Items.
A similar —projection-expression option to the GetItem call we previously looked at is available with the Query API function. By doing so, you can restrict the Items to only return the properties that matter to you.
For instance, we might give the following projection expression if we just wanted to return the Amounts for Daffy’s Orders:
$ aws dynamodb query \
--table-name UserOrdersTable \
--key-condition-expression "Username = :username" \
--expression-attribute-values '{
":username": { "S": "daffyduck" }
}' \
--projection-expression 'Amount' \
$LOCALAnd the only information in the reply is the amount:
{
"Count": 4,
"Items": [
{
"Amount": {
"N": "88.3"
}
},
{
"Amount": {
"N": "18.95"
}
},
{
"Amount": {
"N": "116.86"
}
},
{
"Amount": {
"N": "6.98"
}
}
],
"ScannedCount": 4,
"ConsumedCapacity": null
}Notably, the “Count” key in each of the two answers thus far indicates the number of Items that were returned. The —select option will yield the count of Items that satisfy a Query if that is all you want to know:
$ aws dynamodb query \
--table-name UserOrdersTable \
--key-condition-expression "Username = :username" \
--expression-attribute-values '{
":username": { "S": "daffyduck" }
}' \
--select COUNT \
$LOCALAnd the response:
{
"Count": 4,
"ScannedCount": 4,
"ConsumedCapacity": null
}We went over the fundamentals of the Query API call in this course. Though I believe it to be DynamoDB’s most potent feature, its full potential necessitates proper data modeling.