As your career as a developer progresses, you’ll be expected to think more about software architecture and system design. It is critical to be able to design efficient systems and make tradeoffs on a large scale. System design is a broad field that encompasses many critical concepts. The CAP theorem is a fundamental concept in system design. Understanding the CAP theorem is essential for designing robust distributed systems. Today, we’ll delve deeper into the CAP theorem, explaining what it means and how it works.
But what exactly is the CAP theorem?
The CAP theorem, also known as Brewer’s theorem, is a fundamental theorem in system design. Eric Brewer, a computer science professor at U.C. Berkeley, first presented it in 2000 during a talk on the principles of distributed computing. Nancy Lynch and Seth Gilbert of MIT published a proof of Brewer’s Conjecture in 2002. According to the CAP theorem, a distributed system can only provide two of three properties at the same time: consistency, availability, and partition tolerance. When there is a partition, the theorem formalizes the tradeoff between consistency and availability.
A distributed system is a group of computers that collaborate to create a single computer for end users. All distributed machines share the same state and run concurrently. Users must be able to communicate with any of the distributed machines without realizing it is only one machine in a distributed system. The distributed system network stores data on multiple nodes at the same time, using multiple physical or virtual machines.
Is there proof about CAP theorem?
Consider a distributed system with two nodes:
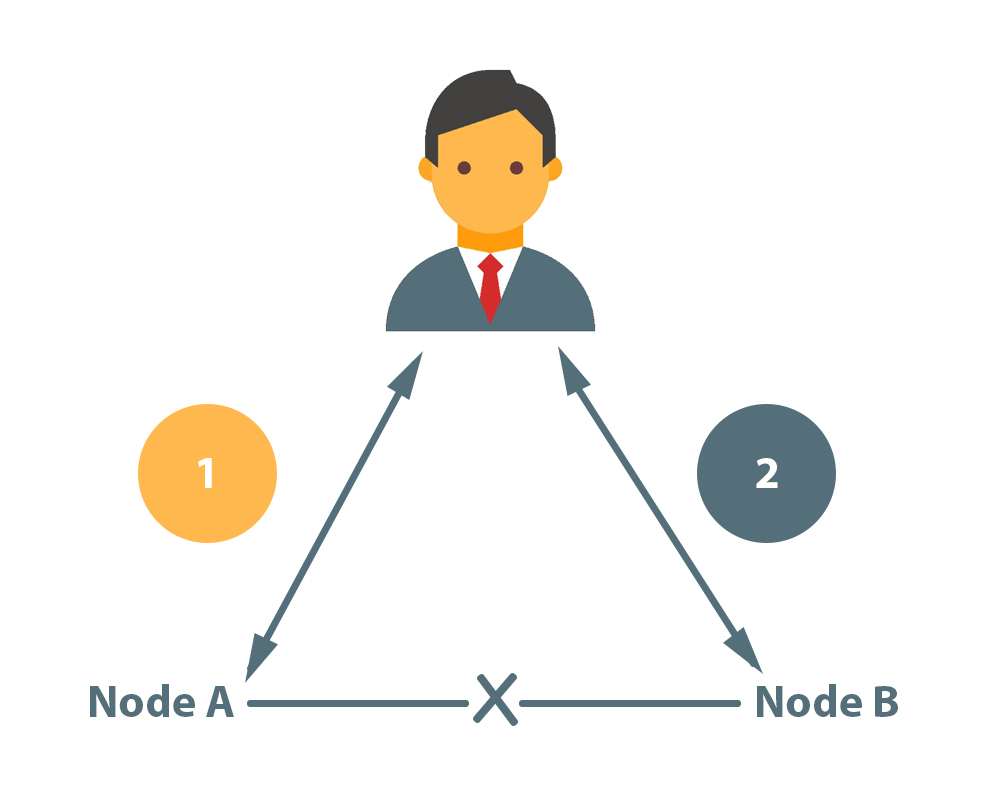
With the value of variable X, the distributed system acts as a plain register. A network failure occurs, resulting in a network partition between the two system nodes. An end-user performs a write request, and then a read request. Consider the case where each request is handled by a different system node. Our system has two options in this case:
- It may fail at one of the requests, causing the system to become unavailable.
- It can execute both requests, returning a stale value from the read request and causing the system’s consistency to be broken.
The system is unable to process both requests while also ensuring that the read returns the most recent value written by the write. Because of the network partition, the results of the write operation cannot be propagated from node A to node B.
Now that we’ve covered the basics of the CAP theorem, let’s break down the acronym and go over the definitions of consistency, availability, and partition tolerance.
Consistency
In a consistent system, all nodes see the same data at the same time. When we perform a read operation on a consistent system, the value of the most recent write operation should be returned. All nodes should return the same data as a result of the read. Regardless of which node they connect to, all users see the same data at the same time. When data is written to a single node, it is replicated across the system’s nodes.
Availability
When availability exists in a distributed system, it means that the system is always operational. Regardless of the individual state of the nodes, every request will receive a response. This means that the system will continue to function even if multiple nodes fail. There is no guarantee that the response will be the most recent write operation, unlike in a consistent system.
Tolerance for partitions
When a distributed system encounters a partition, it means that communication between nodes has been disrupted. If a system is partition-tolerant, it will not fail even if messages are dropped or delayed between nodes within the system. To achieve partition tolerance, the system must replicate records across node and network combinations.
NoSQL databases and the CAP theorem
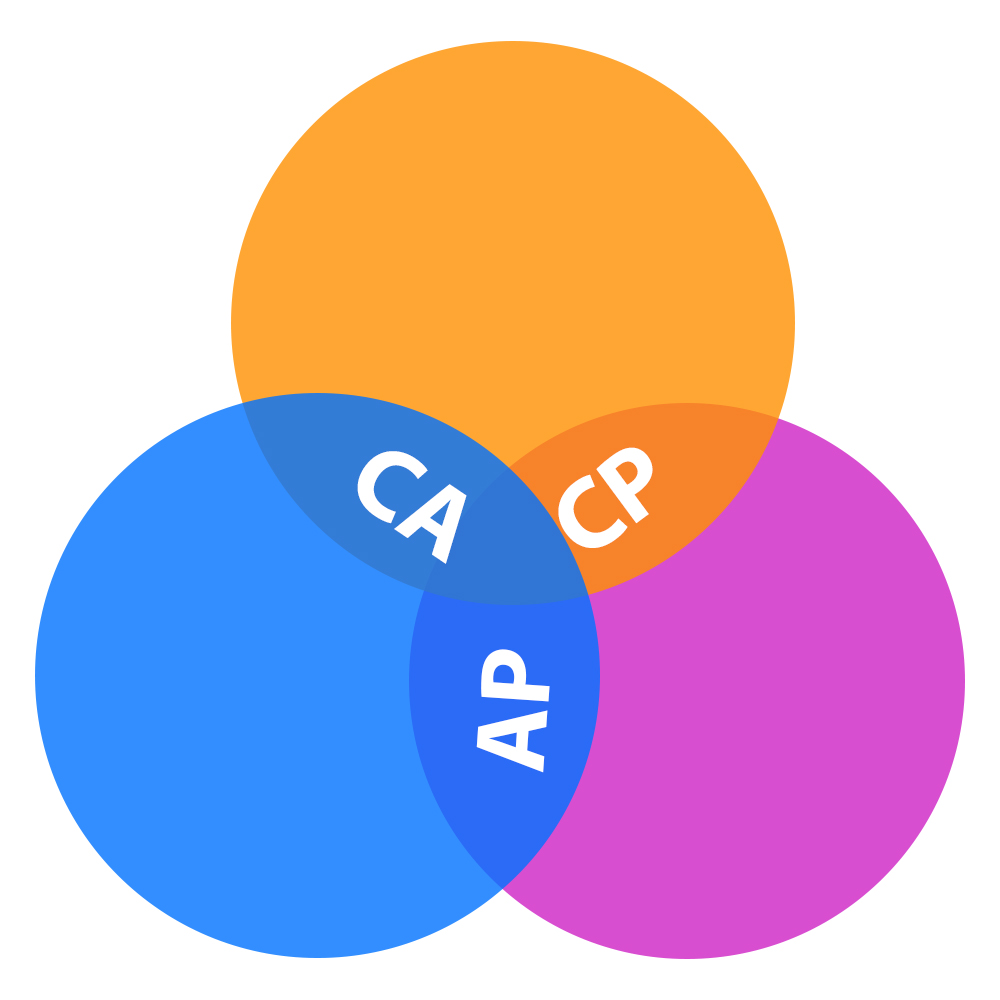
For distributed networks, NoSQL databases are ideal. They support horizontal scaling and can rapidly scale across multiple nodes. It’s critical to remember the CAP theorem when deciding which NoSQL database to use. NoSQL databases are classified according to the two CAP features that they support:
CA’s database
CA databases ensure consistency and uptime across all nodes. Unfortunately, CA databases are incapable of providing fault tolerance. Partitions are unavoidable in any distributed system, so this type of database isn’t a viable option. Having said that, if you require a CA database, you can still find one. PostgreSQL and other relational databases support consistency and availability. Replication can be used to deploy them to nodes.
Databases for AP
Partition tolerance and availability are enabled by AP databases, but not consistency. In the event of a partition, all nodes are accessible, but not all are updated. For example, if a user attempts to access data from an invalid node, they will not receive the most recent version of the data. When the partition is resolved, most AP databases will sync the nodes to ensure consistency between them. An example of an AP database is Apache Cassandra. It is a NoSQL database with no primary node, which means that all nodes are available. Cassandra supports eventual consistency by allowing users to resync their data immediately after a partition is resolved.
Microservices
Microservices are loosely coupled services that can be developed, deployed, and maintained independently. They each have their own stack, database, and database model, and they communicate with one another via a network. Microservices have grown in popularity in hybrid cloud and multi-cloud environments, as well as in on-premises data centers. If you want to build a microservices application, you can use the CAP theorem to help you choose the best database for your needs.